روش ارتباطی یک به یک که در آن یک دستگاه دادهها را به دستگاه دیگر ارسال میکند.





Topology Database یکی از اجزای اساسی در پروتکلهای مسیریابی Link-State مانند OSPF (Open Shortest Path First) و IS-IS (Intermediate System to Intermediate System) است که اطلاعات توپولوژی شبکه را ذخیره میکند. این پایگاه داده شامل اطلاعات دقیق در مورد وضعیت لینکها، روترها، و ارتباطات بین روترها در شبکه است. Topology Database به پروتکلهای مسیریابی کمک میکند تا تصمیمات بهینهتری در مورد انتخاب مسیرهای دادهها بگیرند و عملکرد بهتری در مسیریابی داشته باشند. در این مقاله، به بررسی مفهوم Topology Database، نحوه عملکرد آن، و نقش آن در پروتکلهای مسیریابی خواهیم پرداخت.
در پروتکلهای Link-State، هر روتر یک پایگاه داده وضعیت لینک (LSDB) دارد که اطلاعات توپولوژی شبکه را از سایر روترها دریافت و ذخیره میکند. این اطلاعات بهطور مداوم بهروزرسانی میشود و به روترها این امکان را میدهد که از بهترین مسیرهای ممکن برای ارسال بستههای داده استفاده کنند.
Topology Database یا پایگاه داده توپولوژی شبکه، یک ساختار داده است که اطلاعات دقیق در مورد وضعیت لینکها، روترها و ارتباطات بین روترها را در یک شبکه ذخیره میکند. این پایگاه داده معمولاً در پروتکلهای مسیریابی Link-State مانند OSPF و IS-IS استفاده میشود. در این پروتکلها، روترها اطلاعات وضعیت لینکها را با یکدیگر به اشتراک میگذارند و Topology Database بهعنوان پایگاهی برای ذخیره این اطلاعات عمل میکند.
هر روتر یک نسخه محلی از Topology Database خود را نگهداری میکند که شامل اطلاعات بهروز از شبکه است. این اطلاعات شامل وضعیت هر لینک (فعال یا غیرفعال)، هزینههای هر لینک، و اتصالهای بین روترهای مختلف است. هنگامی که توپولوژی شبکه تغییر میکند، اطلاعات موجود در پایگاه داده بهطور خودکار بهروزرسانی میشود.
عملکرد Topology Database بهطور عمده بر اساس تبادل اطلاعات وضعیت لینکها بین روترها است. در این پروسه، هر روتر اطلاعات وضعیت لینکهای خود را بهطور دورهای به سایر روترها ارسال میکند. این اطلاعات پس از دریافت، در پایگاه داده توپولوژی ذخیره میشود و بهطور خودکار جدولهای مسیریابی روتر بهروز میشود. مراحل عملکرد Topology Database به شرح زیر است:
Topology Database مزایای زیادی برای شبکهها و پروتکلهای مسیریابی دارد که بهویژه در شبکههای بزرگ و پیچیده اهمیت دارد. برخی از مزایای آن عبارتند از:
با وجود مزایای زیاد، Topology Database نیز معایب خاص خود را دارد که باید در نظر گرفته شوند. برخی از معایب آن عبارتند از:
Topology Database در پروتکلهای مسیریابی Link-State مانند OSPF و IS-IS کاربرد دارد. برخی از کاربردهای اصلی آن عبارتند از:
Topology Database یکی از اجزای اساسی پروتکلهای مسیریابی Link-State مانند OSPF است که اطلاعات دقیق در مورد وضعیت لینکها و توپولوژی شبکه را ذخیره میکند. این پایگاه داده به پروتکلهای مسیریابی کمک میکند تا بهترین مسیرها را برای ارسال دادهها انتخاب کنند و از بهروزرسانیهای دقیق توپولوژی شبکه بهرهبرداری کنند. با وجود مزایای زیادی که Topology Database دارد، مانند دقت بالا و مقیاسپذیری، این ویژگی نیز معایبی مانند مصرف منابع بیشتر و پیچیدگی در پیادهسازی دارد. برای درک بهتر نحوه عملکرد Topology Database و بهینهسازی استفاده از آن در شبکه، میتوانید به سایت saeidsafaei.ir مراجعه کنید.
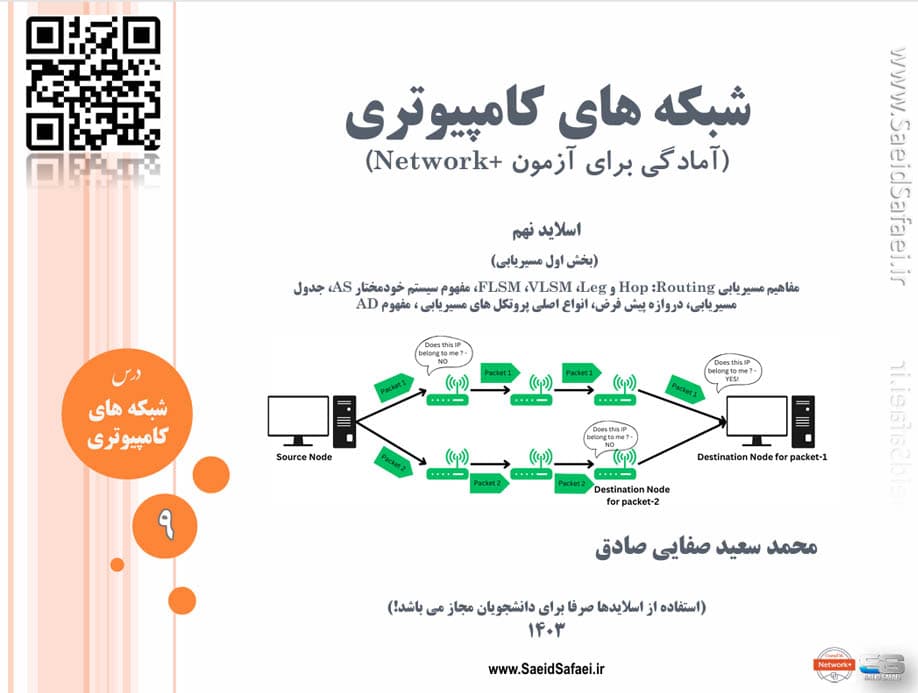
در این جلسه (بخش اول مسیریابی)، مفاهیم پایهای مسیریابی (Routing) مانند Hop، InterVLAN و Leg بررسی میشوند. سپس، تکنیکهای VLSM (Variable Length Subnet Mask) و FLSM (Fixed Length Subnet Mask) توضیح داده میشوند. همچنین، مفهوم سیستم خودمختار (AS) و اهمیت آن در مسیریابی، ساختار جدول مسیریابی و نقش دروازه پیشفرض بررسی خواهد شد. در نهایت، انواع کلاسهای پروتکلهای مسیریابی معرفی و ویژگیهای آنها مورد بحث قرار میگیرد. هدف این جلسه، درک اصول مسیریابی و نحوه مدیریت مسیرها در شبکههای پیچیده است.
روش ارتباطی یک به یک که در آن یک دستگاه دادهها را به دستگاه دیگر ارسال میکند.
شبکهای که مساحتی وسیعتر از یک LAN پوشش میدهد و معمولاً برای ارتباطات بین کشورها و قارهها استفاده میشود.
سیستمهای خود-تطبیقی به سیستمهایی اطلاق میشود که قادر به شبیهسازی و انطباق با شرایط و تغییرات محیطی بهطور خودکار هستند.
دستیارهای دیجیتال هوشمند به سیستمهایی اطلاق میشود که از هوش مصنوعی برای ارائه خدمات به کاربران بهطور شخصی و کارآمد استفاده میکنند.
تخصیص حافظه به معنای اختصاص بخشهای مختلف حافظه به آرایهها یا متغیرها است. تخصیص حافظه برای آرایههای داینامیک در زمان اجرا انجام میشود.
زیستشناسی مصنوعی به استفاده از مهندسی ژنتیک و فناوریهای بیولوژیکی برای طراحی و ساخت موجودات مصنوعی گفته میشود.
عبور پیش از پیش به معنای بازدید از گرهها به ترتیب: ابتدا گره ریشه، سپس گرههای زیرین به ترتیب پیشاز پیش.
حلقه for برای اجرای دستورالعملها به تعداد مشخص استفاده میشود. این حلقه معمولاً برای تکرار عملیاتهایی که تعداد مشخصی دارند، مفید است.
پردازش زبان طبیعی (NLP) به استفاده از الگوریتمهای هوش مصنوعی برای تحلیل و درک زبانهای انسانی اشاره دارد.
الگوریتم مرتبسازی به فرآیند مرتب کردن عناصر یک آرایه یا لیست بر اساس ترتیب خاص گفته میشود.
ساخت دیجیتال به استفاده از فناوریهای دیجیتال برای طراحی و ساخت محصولات فیزیکی و مدلهای پیچیده اطلاق میشود.
مجموعهای از گرهها یا دستگاهها که با استفاده از اتصالات مختلف (سیمی یا بیسیم) به یکدیگر متصل شدهاند و به تبادل دادهها میپردازند.
حالت انتقال داده یک طرفه که در آن فقط یک دستگاه میتواند دادهها را ارسال کند یا دریافت کند.
سیستمهای دفترکل توزیعشده (DLS) به استفاده از شبکههای غیرمتمرکز برای ذخیرهسازی و مدیریت دادهها با شفافیت و امنیت اشاره دارد.
سیگنال دیجیتال یک نوع سیگنال است که در آن اطلاعات به صورت دادههای دیجیتال (0 و 1) منتقل میشوند.
خروجی به نتایج حاصل از پردازش دادهها گفته میشود که پس از انجام عملیاتها به کاربر یا سیستم دیگری ارسال میشود.
مکانیزمی در زبانهای برنامهنویسی مانند C++ که به شما اجازه میدهد تا به آدرسهای حافظه اشاره کنید.
الگوریتم مرتبسازی انتخابی بر اساس انتخاب کوچکترین یا بزرگترین عنصر در هر مرحله و جابهجایی آن با مکان مناسب عمل میکند.
آرگومان دادهای است که به تابع ارسال میشود. این دادهها هنگام فراخوانی تابع به پارامترهای آن منتقل میشوند و در داخل تابع به عنوان متغیرهایی برای پردازش مورد استفاده قرار میگیرند.
دستگاههای ورودی مانند موس و کیبورد که اطلاعات را به کامپیوتر وارد میکنند.
عملگرهای ریاضی برای انجام عملیاتهایی مانند جمع، تفریق، ضرب و تقسیم روی دادهها استفاده میشوند.
ابعاد آرایه به تعداد محورهایی گفته میشود که دادهها در آنها سازماندهی شدهاند. آرایهها میتوانند یکبعدی، دوبعدی، یا چندبعدی باشند.
لیست پیوندی دایرهای نوعی از لیست پیوندی است که در آن آخرین عنصر به اولین عنصر اشاره دارد.
وسایل نقلیه خودران به خودروهایی گفته میشود که بدون نیاز به راننده انسان حرکت میکنند.
اینترنت کوانتومی به شبکهای گفته میشود که بر اساس اصول فیزیک کوانتومی برای انتقال دادهها با امنیت بالا عمل میکند.
پروتکل مسیریابی Link State که از الگوریتم Dijkstra برای محاسبه کوتاهترین مسیر استفاده میکند.
شرط به معنای مقایسهای است که باید در حلقهها یا دستورات شرطی بررسی شود. شرط اگر درست باشد، عمل خاصی اجرا خواهد شد.
اضافه بار یا اوورفلو زمانی رخ میدهد که سیستم محاسباتی نمیتواند عددی بزرگتر از ظرفیت ذخیرهسازی خود را پردازش کند.
گردوغبار هوشمند به سنسورها و دستگاههای ریز اشاره دارد که در مقیاس میکرو برای جمعآوری اطلاعات از محیط اطراف استفاده میشوند.
شبکههای عصبی شناختی به شبکههایی اطلاق میشود که سعی در شبیهسازی مغز انسان برای انجام پردازشهای پیچیده دارند.
تولید زبان طبیعی به فرآیندی گفته میشود که در آن ماشینها قادر به تولید متن و محتوای طبیعی مشابه انسان میشوند.
یک ترابایت معادل 1024 گیگابایت است و برای اندازهگیری حجمهای بسیار زیاد دادهها استفاده میشود.
آگاهی مصنوعی به ایجاد سیستمهای هوش مصنوعی اطلاق میشود که قادر به تجربه و درک مشابه انسانها باشند.
اولین و مهمترین سوئیچ در شبکه که مسئول تعیین بهترین مسیرها برای ارسال دادهها است.
محاسبه یک فرآیند عددی است که معمولاً با استفاده از ابزارهای محاسباتی مانند ماشین حساب یا نرمافزارهای خاص انجام میشود. محاسبات معمولاً برای تجزیه و تحلیل دادههای عددی انجام میگیرد.
